When to use Selenium or Cypress
So if you're looking to write a suite of automated end-to-end tests for your website, but aren't sure what tool to use, let me provide you with my recommendation based on my experience building test frameworks.
These recommendations are based purely on my own opinion, having used both Cypress and Selenium for roughly six years.
Quick disclaimer though: For those of you that are building a website using a templated tool such as Wordpress, you're most likely going to be perfectly okay using either product.
Selenium's market share
When we look at who the current go-to product is, it's Selenium.
Selenium has existed since 2004 and is well known for providing really good cross-browser support as well as supporting a large number of languages. This tool has a number of other useful features that allow it to not only act as an automated testing tool but an automation tool overall.
There are companies out there that automate their payroll or other manual administrative tasks using this library.
While Selenium is a powerful tool, there are drawbacks due to the way it was designed that I think limits its usage in today's web.
Language support
When we look at language support, Selenium is the clear winner.
One thing to consider when designing a test suite for an application written in an Object Oriented language is to consider whether the models available in the application could be used for testing purposes as well.
I've previously designed automation frameworks in .NET that were directly included in the main application's repo, allowing us to reference the main app's project in Visual Studio and get access to the models within the application.
Why would you do this? For one it saves quite a bit of time when writing up the initial models in your test framework, but also if you ever need to access an application's database.
See, the test framework I wrote needed to confirm as part of the end to end testing that something showed up in a database, and since the application was written using the Entity Framework model, we could simply use the application models when reading the database content.
Stale elements
Selenium has a concept of a 'stale element' - that is an element that was on the page a moment ago but is now different or missing.
Stale elements can happen when the content of a web page is updated or refreshed asynchronously, which is a common occurrence in modern web applications built with frameworks like React, Angular, or Vue.js.
Why does this happen? Well Selenium is built using client/server architecture as shown below:
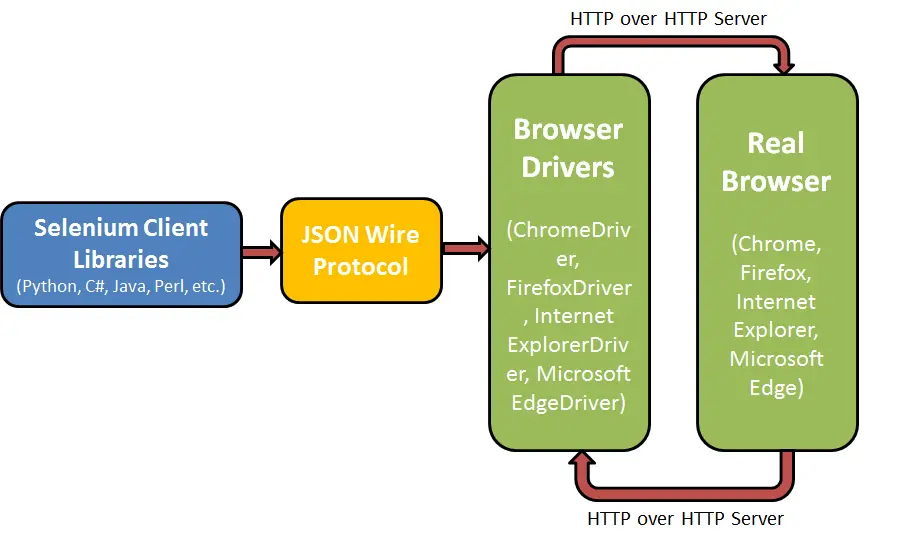
In the short timespan between these requests, the page can change. Since Selenium keeps a reference to the element based on its initial location in the DOM, any changes that occur during this short window of time can result in an invalid element.
This limitation becomes a significant drawback in today's web development landscape for several reasons:
Dynamic Content Updates: Modern web applications often update their content dynamically without refreshing the entire page. This dynamic nature can lead to frequent changes in the DOM, causing elements to become stale more frequently.
Single-Page Applications (SPAs): Frameworks like React enable the development of SPAs where content is loaded asynchronously. As a user interacts with different components, the DOM structure can change dynamically, making it challenging for Selenium to maintain stable references to elements.
Increased Test Maintenance: Dealing with Stale Elements adds complexity to test scripts and requires developers/testers to implement workarounds such as refreshing the page or re-finding elements. This increases test maintenance efforts and can lead to brittle test scripts.
Reduced Reliability: Stale Elements introduce a level of unpredictability in test automation, leading to flakiness and unreliable test results. This undermines the purpose of automation, which is to provide consistent and accurate testing.
To try to avoid these issues, Selenium users often resort to using explicit waits, refreshing the page, or re-finding elements before interacting with them. However, this doesn't fix the underlying issue and only adds more overhead to an already flakey test.
This is in my opinion Selenium's biggest flaw, and not one that they will likely ever fix.
Cypress on the other hand does not have these issues.
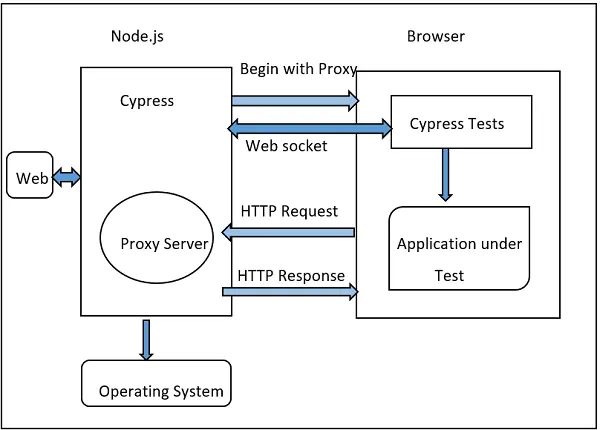
Due to its architecture, Cypress has some significant advantages:
- Cypress has direct access to the DOM. This allows Cypress to maintain a real-time view of the DOM and easily handle dynamic changes.
- Cypress executes commands sequentially in a command queue, ensuring that each command waits for the previous one to complete. This eliminates race conditions and timing issues that often lead to Stale Element problems in Selenium.
- Cypress automatically waits for elements to become available and interactable before executing commands. This eliminates the need for explicit waits and reduces the likelihood of encountering Stale Element issues.
- Cypress automatically retries commands and assertions until they pass or reach a timeout. This means that if an element becomes stale momentarily, Cypress intelligently handles it without crashing your tests.
Because of this, if you find yourself building applications in any of the above frameworks, or find yourself writing tests for something that changes rapidly depending on user input then save yourself the headaches and just go straight for Cypress.