Managing context for agentic development
Context is quickly becoming a hot topic for those of us using agentic AI as part of our daily development workflows. A well thought out, single topic session can provide significant improvements over a long-running conversation with significant MCP tool usage. The difference in quality-of-output between simple tasks, such as "Fix this specific bug" and "Perform an entire rewrite of the frontend" are noticeable.
So how do we effectively manage context when working with Claude Code, GitHub CoPilot, OpenCode or (insert new tool everyone is using by the time you read this here) to ensure we get the most out of our token spend?
What makes up our context window?
System prompt
Ah yes, the system prompt. My understanding of the system prompt is that it differs based on which tool you're using. GitHub CoPilot for example has a system prompt outlining general instructions, expected behavior of the agent, available tools, how to patch code, formatting rules and any *.instructions.md file you've created in .github/copilot-instructions.md
For more details on CoPilot's system prompt, this LinkedIn article sheds some light. System prompts will contain a range of rules and guardrails to ensure that the conversation stays within appropriate boundaries. An example of a refusal rule might be around asking the agent to produce malicious code.
Chat history
Every message you've ever sent up until now feeds into the agent. If you hold a long running conversation with an agent, you'll often find it begins to 'factor in' previous discussions or messages into new outputs.
MCPs
Unlike the newly introduced Claude Skills, MCP servers are always loaded into the conversation, because the LLM needs to be aware of which tools are available at any given moment. It makes sense, because half-way through a conversation maybe your agent will want to make use of the Chrome DevTools MCP to test a feature visually (which works great, by the way)
The problem is that each endpoint within an MCP needs to be loaded, even if it would never get used. Look at this example from VS Code, which shows 37 tools, the majority of which are 'built in'.
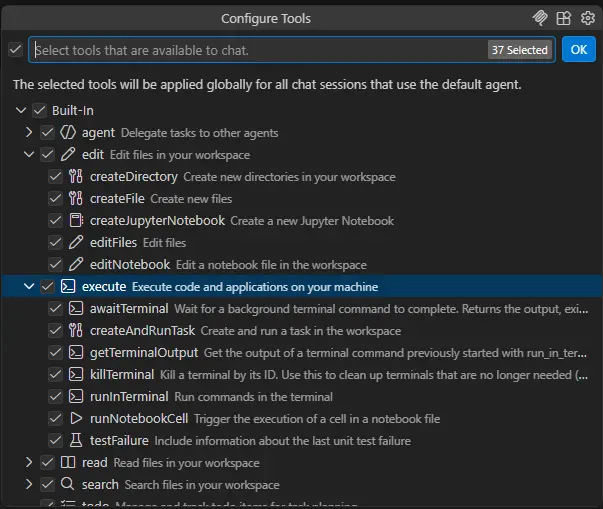
Each new MCP server we add and keep enabled during a conversation is slightly more context space we've lost for more important things, like conversation.
How a full context window slows us down
I recently ran an experiment with a repo I commonly work on, where I wanted to essentially introduce falsified information about the repo and see how long the agent would work with that info without challenging it, effectively poisoning the context.
The idea behind this is that as developers, sometimes we look into red herrings during debugging or development. Not every technical decision pans out because we're human. We might make a decision to write a function a certain way only to find out somewhere else in the codebase there would be an impact.
But the problem with developing alongside agentic AI in this manner is it doesn't quite yet fully compartmentalize that information like we do as humans, so it can bring this stuff up later in its decision making.
To test this out I took Claude Sonnet 4.6 on a long-running, essentially unending conversation (right until I hit about 75% context window length and GitHub CoPilot was about to force compaction) in the aforementioned codebase.
I also purposefully mentioned a non-existent plan to build a feature (such as "we're planning on adding x feature in future, how would that look?") as well as a bug I thought existed in how some filtering logic worked. The agent investigated this bug and identified it did not in fact exist.
The last message I sent in this conversation was to document how the app works "for a new starter" and save it to Markdown.
The result? Explicit call outs to the previous fake feature, and the model treated the one file I had previously attached as context as if that file was the driving logic behind the app, even though that's not true. The agent also mentioned "possible bug in x" despite knowing and having confirmed first hand that the bug did not in fact exist. Whilst it did make these callouts, it left them as essentially footnotes at the end of the document.
It essentially tells us that chat history impacts future output, but to what extent is still unclear
How can we manage context better?
Establishing a pattern of when to kill chat sessions and create new ones will probably have the highest return out of any of these suggestions. For example, I'll briefly summarize how I began to identify when to kill sessions during development.
Kill sessions often
Switching context between researching, planning, actively writing code and testing code is worthy of a new session. Think about how quality assurance has worked in the software development industry, where testers who do not have knowledge of the app code test the end user experience, treating the app as a black box. Why should your agent test the code it already knows about, and understands previous technical decisions? This simply invites the possibility of bias.
Before a feature, there's a chance I'll need to research the codebase a bit. Have we previously made similar changes before? How does the app work overall? What does the API look like. Depending on how often you change between codebases and how many people work on those codebases, this could be an entire chat session on its own.
Once we have a solid understanding of the codebase, it might be possible that we've found a hidden can of worms that might come up later. If so I'll simply direct the agent to document this specific issue and only this issue as a markdown file.
Next, we'll go into plan mode (and import the previous markdown file if we created one). This is when I usually break out Claude Opus and begin blowing through my monthly limit. I'll get Opus to write up a solid implementation plan for the feature we'll build, and I'll review it.
Now at this point, whether we write this plan out to a file and create a new session or not depends solely on whether or not a "back and forth" conversation has occurred. If Opus 'one shotted' the plan, then it doesn't matter whether the information is in a file or not, we still need this context.
If however there was a back and forth conversation, then I have no reason for anything prior to the 'final version' of our plan to remain in context. Lastly, we'll switch back to Sonnet 4.6 to simply follow the plan and implement.
Any time I finish a feature, I'll kill the session and create a new one. While the agent will make an attempt to understand the code, it should not have as deep of an understanding as the previous conversation where it gamed out exactly how the feature should work. This also allows the agent to ensure the tests written or performed match others in the project, as the entire session focus has shifted from writing code to testing a feature.
Limit MCP tools, use CLIs
This has been more of a shift I've been seeing across the industry lately, but there is something to be said about avoiding MCPs if a CLI already exists.
Back when MCP servers were first released, the industry exploded with interest. All of a sudden GitHub repos were dedicated to listing the cool MCP servers that are available (and looking at my scroll bar on that page, there's a lot)
However, as we install more and more of these servers into our environment, they take up more and more of the context window. While disabling MCPs is possible in VS Code's CoPilot, it's not always possible everywhere else.
It's worth nothing too that we don't need MCPs specifically for things like GitHub, or BuildKite. CLIs already exist for both of them as gh and bk respectively. These CLIs will be called by the agent without needing to clog up the context window unnecessarily, so it's worth keeping as an option.
Continue to experiment
Continuing to experiment with agents and how they behave during long conversations has considerably helped my understanding of when and when not to kill sessions, shift the conversation, or provide different instructions.
As agents however continue to improve in this area (with Sonnet 4.6 performing noticably better in this area than 4.5 in my opinion) we may soon reach a day where context management is no longer even necessary.